Алексей++
глобальный и пушистый
Глобальный модератор
 - Chelyabinsk - Chelyabinsk")
 Offline Offline
Сообщений: 13
|
 |
« : 09-10-2015 07:03 » |
|
имеется составной индекс по полям
f1,f2,f3,f4
(- порядок в индексе указан такой)
Но сами поля создавались в другом порядке, скажем
f0
f3
f1
f4
f5
f2
f6
Вопрос: порядок создания полей, отличный от порядка, указанного в составном индексе, повлияет как-то на скорость поиска по этому индексу ?
|
|
|
|
|
 Записан
Записан
|
|
|
|
|
Sla
|
|
« Ответ #1 : 09-10-2015 07:56 » |
|
С чего бы?
|
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
|
Dale
|
|
« Ответ #2 : 09-10-2015 09:21 » |
|
Насколько я помню, на скорость поиска по составному индексу сильнее всего влияет селективность по данному полю, т.е. если поля с высокой селективностью идут первыми, то поиск по индексу производится быстрее. Но занимался этим давненько, поэтому могу и ошибаться.
|
|
|
|
|
Записан
|
Всего лишь неделя кодирования с последующей неделей отладки могут сэкономить целый час, потраченный на планирование программы. - Дж. Коплин.
Ходить по воде и разрабатывать программное обеспечение по спецификациям очень просто, когда и то, и другое заморожено. - Edward V. Berard
Любые проблемы в информатике решаются добавлением еще одного уровня косвенности – кроме, разумеется, проблемы переизбытка уровней косвенности. — Дэвид Уилер.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #3 : 09-10-2015 12:32 » |
|
Sla, Dale,
ну, то есть, от порядка создания напрямую не зависит, зависит от содержимого
Хорошая селективность - это, насколько я понял, когда значений у индекса много (в идеале - все значения разные, например, в автоинкрементном поле) , а плохая - когда одно-пара значений
Попозже ещё вопросы позадаю по оптимизации запроса, я плаваю в этом вопросе конкретно ))
Пока экспериментирую и ковыряю - велено написать большой запрос для создания отчётов
|
|
|
|
|
Записан
|
|
|
|
|
Dale
|
|
« Ответ #4 : 09-10-2015 13:15 » |
|
Когда я занимался задачами оптимизации запросов к БД, постоянно держал под рукой эту книгу: Рецепты заточены под другие СУБД, но подход в основном платформенно-независимый. Настоятельно рекомендую. |
|
|
|
|
Записан
|
Всего лишь неделя кодирования с последующей неделей отладки могут сэкономить целый час, потраченный на планирование программы. - Дж. Коплин.
Ходить по воде и разрабатывать программное обеспечение по спецификациям очень просто, когда и то, и другое заморожено. - Edward V. Berard
Любые проблемы в информатике решаются добавлением еще одного уровня косвенности – кроме, разумеется, проблемы переизбытка уровней косвенности. — Дэвид Уилер.
|
|
|
|
Sla
|
|
« Ответ #5 : 09-10-2015 18:02 » |
|
вот смотри 1
SELECT * FROM product p
LEFT JOIN product_description pd ON (p.product_id=pd.product_id AND pd.language_id=1)
WHERE ...
2
SELECT * FROM product p
LEFT JOIN product_description pd ON (p.product_id=pd.product_id)
WHERE pd.language_id=1
AND ...
3
SELECT * FROM product p
JOIN product_description pd ON (p.product_id=pd.product_id)
WHERE pd.language_id=1
AND ...
product_i -> AI и следовательно индекс Можно построить индекс по pd.product_id и pd.language_id Кстати... для размышления Какой селект менее нагрузочный? Т.е. к индексам нужно подходить осторожно. Если, например наличие индекса при выборке может ускорить запрос, то при создании - замедлить. В качестве ключей нужно использовать поля по которым чаща всего идет отбор. |
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #6 : 10-10-2015 05:40 » |
|
Sla, 1 и 2 - вроде разные результаты выдадут, как тут нагрузку сравнивать ? В третьем join по умолчанию тоже left будет ?
Индексы добавил, выбираться гораздо шустрее стало. Насчёт тормозов при вставке - вроде терпимо добавляется, нет жалоб пока ))
Добавлено через 5 минут и 26 секунд:
Dale, а в электрическом виде в PDF есть такая ? Нашёл в дежавю только hproklondike.com/books/dbobshee/tou_sql_tuning.html
|
|
|
|
« Последнее редактирование: 10-10-2015 05:45 от Алексей1153 »
|
Записан
|
|
|
|
|
Dale
|
|
« Ответ #7 : 10-10-2015 21:10 » |
|
Dale, а в электрическом виде в PDF есть такая ? Лично у меня нет. У меня в те времена еще не было электрокниги, и я покупал бумажные в "Озоне". А сейчас уже не работаю так активно с базами данных и не собираю книги по ним. Может, еще эта окажется полезной: http://it-ebooks.ru/publ/dbms/mysql_performance_optimization/22-1-0-303 |
|
|
|
|
Записан
|
Всего лишь неделя кодирования с последующей неделей отладки могут сэкономить целый час, потраченный на планирование программы. - Дж. Коплин.
Ходить по воде и разрабатывать программное обеспечение по спецификациям очень просто, когда и то, и другое заморожено. - Edward V. Berard
Любые проблемы в информатике решаются добавлением еще одного уровня косвенности – кроме, разумеется, проблемы переизбытка уровней косвенности. — Дэвид Уилер.
|
|
|
|
RXL
|
|
« Ответ #8 : 10-10-2015 23:38 » |
|
Вопрос: порядок создания полей, отличный от порядка, указанного в составном индексе, повлияет как-то на скорость поиска по этому индексу ?
Ни на что не влияет. Индексы хранятся в b-tree отдельно от данных. |
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #9 : 11-10-2015 07:58 » |
|
Dale, спасибо, я дежавюшную начал уже читать, даже кое-что проясняется в голове ))
RXL, поверю )
|
|
|
|
|
Записан
|
|
|
|
|
Sla
|
|
« Ответ #10 : 11-10-2015 13:13 » |
|
Да, 2-й и 3-й это одинаковые запросы
2-й вырождается в JOIN
1-й и 2-й могут дать и разный и один и тот же результат
Все зависит от product_description
Но пример я привел для другой цели
Чтоб показать, что в первом джойнится не вся таблица pd, а уже отобранная.
Причем, не знаю как в mySQL, но на ORACLE порядок в услвиях WHERE мог существенно ускорить запрос
в mySQL заметил особенность, что LEFT JOIN почему-то быстрее работает, не на много, но быстрее
проверялось это на 2-м и 3-м запросах . В причинах не разбирался.
|
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
|
RXL
|
|
« Ответ #11 : 11-10-2015 17:44 » |
|
Я исходил бы от запросов, какие поля они определяют однозначно (через "="), какие через IN или связку с другой таблицей, а какие нужно достать или использовать в group by и order by. 1-й и 2-й могут дать и разный и один и тот же результат
Все зависит от product_description
1-й вернет строку product всегда, второй вернет только если есть соответствующая строка в product_description. Т.ч. я бы их даже близко не сравнивал. Надо исходить от необходимого результата. Добавлено через 5 минут и 19 секунд:Причем, не знаю как в mySQL, но на ORACLE порядок в услвиях WHERE мог существенно ускорить запрос
Зависит от версии Oracle. В древних версиях (8 и ниже) могло влиять. В MySQL порядок не важен - оптимизатор все равно перепишет запрос. в mySQL заметил особенность, что LEFT JOIN почему-то быстрее работает, не на много, но быстрее
проверялось это на 2-м и 3-м запросах . В причинах не разбирался.
Это не правило. Надо проверять на EXPLAIN и разбираться с конкретным случаем и особенно с используемыми индексами. Про сортировку вообще отдельный разговор. Кроме того в 5.х есть ручное планирование использования индексов. |
|
|
|
« Последнее редактирование: 11-10-2015 17:49 от RXL »
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #12 : 12-10-2015 06:11 » |
|
есть запрос примерно такого вида (вырезал из рабочего запроса лишнее, чтобы не наврать) таблица t1 уже отсортирована по event_id (это индекс, так что, по идее, сортировка тут быстрая ). Но после объединения в результате порядок всё равно неправильный. Приходится после всего запроса выполнять сортировку заново (в explain при этом появляется действие filesort) Почему сортировка нарушается после объединения, и снова требуется сортировать ? Или там сортировка уже всё равно не займёт много времени ? Однако она там нужна, иначе нет порядка в event_id select
t1_event_id as event_id
, t1_Task_guid as Task_guid
, ...
from
(
select
`event_id` t1_event_id
,`event_code` t1_event_code
,`Task_guid` t1_Task_guid
from `events_table`
where
`event_code` in( 4,7,8,15)
order by `event_id` desc -- тут я сортирую до объединения, как мне казалось
)t1
left join
( -- присоединяю дополнительную инфу к t1_event_code=4
select
...
from `events_table`
...
)t2
on
(
...
and t1.t1_event_code=4
)
order by `event_id` desc -- оказывается, тут снова нужно отсортировать, иначе нет порядка
; |
|
|
|
« Последнее редактирование: 12-10-2015 09:38 от RXL »
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #13 : 12-10-2015 09:35 » |
|
Леш, покажи SHOW CREATE TABLE и SHOW INDEX FROM используемых таблиц. И результат EXPLAIN SELECT твоего запроса.
Добавлено через 3 минуты и 11 секунд:
Внешний order by приводит к игнору order by в подзапросе.
Вообще общее правило реляционных баз: порядок строк не гарантирован. Не надо рассчитывать на определенный порядок обработки. Скажем, в MySQL group by автоматом дает сортировку по этим же полям, а в PostgreSQL - нет. Т.ч. если приложение сменит СУБД, то будут трудности. Лучше ориентироваться на стандартные правила. И еще: поработав с PostgreSQL, скажу, что это лучше, чем MySQL. Лучше ли PostgreSQL чем Oracle, не скажу, но где-то на уровне и однозначно бесплатнее.
|
|
|
|
« Последнее редактирование: 12-10-2015 09:48 от RXL »
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
|
Sla
|
|
« Ответ #14 : 12-10-2015 10:36 » |
|
есть запрос примерно такого вида (вырезал из рабочего запроса лишнее, чтобы не наврать) таблица t1 уже отсортирована по event_id (это индекс, так что, по идее, сортировка тут быстрая ). Но после объединения в результате порядок всё равно неправильный. Приходится после всего запроса выполнять сортировку заново (в explain при этом появляется действие filesort) Почему сортировка нарушается после объединения, и снова требуется сортировать ? Или там сортировка уже всё равно не займёт много времени ? Однако она там нужна, иначе нет порядка в event_id select
t1_event_id as event_id
, t1_Task_guid as Task_guid
, ...
from
(
select
`event_id` t1_event_id
,`event_code` t1_event_code
,`Task_guid` t1_Task_guid
from `events_table`
where
`event_code` in( 4,7,8,15)
order by `event_id` desc -- тут я сортирую до объединения, как мне казалось
)t1
left join
( -- присоединяю дополнительную инфу к t1_event_code=4
select
...
from `events_table`
...
)t2
on
(
...
and t1.t1_event_code=4
)
order by `event_id` desc -- оказывается, тут снова нужно отсортировать, иначе нет порядка
; ух... мама дАрагая ( select `event_id` t1_event_id ,`event_code` t1_event_code ,`Task_guid` t1_Task_guid from `events_table` where `event_code` in( 4,7,8,15) order by `event_id` desc -- тут я сортирую до объединения, как мне казалось )t1 order by - лишнее Как сказал Рома - последний все сам сделает Но ты вибираешь из двух одинаковых таблиц, т.е. джойнишь их SELECT *
from `events_table`
where
`event_code` in( 4,7,8,15) Объясни, зачем ты присоединяешь вторую, если в `event_code` in( 4,7,8,15) ты уже ее отобрал? |
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
|
RXL
|
|
« Ответ #15 : 12-10-2015 11:14 » |
|
Леш, стоит немного подучить теорию. Особенно отношения зависимых сущностей (строк в разных таблицах) и когда какие надо применять и когда какие допустимо применять.
Типов отношений не так много:
1. has many: строке таблицы t1 соответствует произвольное число строк из таблицы t2 (FROM t1 LEFT JOIN t2)
2. belongs to: обратная has many зависимость: строке в t1 соответствует одна строка в t2 (FROM t1 JOIN t2)
3. has one: связка один-к-одному: строке в t1 соответствует одна строка в t2 (FROM t1 JOIN t2)
4. might have: необязательная связка один-к-одному: строке в t1 может соответствовать одна строка в t2 (FROM t1 LEFT JOIN t2)
5. many to many: более редкий случай - многие-к-многим: для связки используется третья таблица t3 и, в зависимости от выбора, какая сущность будет главной в запросе, зависит форма выборки. Например, если выбирается t1 и относящиеся к ней t2, то many to many переходит в has many с дополнительной таблицей связки (FROM t1 LEFT JOIN t3 LEFT JOIN t2). Если важно выбрать именно связанные сущности, главной таблицей становится t3, при этом порядок объединения не важен. Хотя Oracle может ругаться (не помню точно) и требовать FROM t3, а для MySQL FROM t3 JOIN t1 JOIN t2 эквивалентно FROM t1 JOIN t3 JOIN t2.
|
|
|
|
« Последнее редактирование: 12-10-2015 11:24 от RXL »
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
|
Sla
|
|
« Ответ #16 : 12-10-2015 12:43 » |
|
Леша, ты ж не в первый раз видишь SQL
И не бойся
mySQL от ORACLEsql или MSSql в твоих задачах будет отличаться на на 0,5%
|
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #17 : 12-10-2015 14:49 » |
|
Sla, Объясни, зачем ты присоединяешь вторую, если в `event_code` in( 4,7,8,15) ты уже ее отобрал? в таблице событий некоторые события являются цепочкой одного задания, объединены они одним гуидом в первом селекте выбираются определённые события для отчёта-истории , к ним (там, где событие 4) джойнится дополнительная инфа - время выполнения задания и т.д. Я ковырялся и нашёл только такой способ это выполнить, подскажи, как лучше Sla, RXL, с MSSql столкнулся давеча в предыдущем проекте, как-то мне мускуль всё равно больше нравится. Ну, может просто привычнее. Насчёт PostgreSQL чем Oracle - не сталкивался, ничего не могу сказать. Но и заказчик не поймёт, зачем я ему стану субд вдруг менять )) Сейчас у нас MySQL Ром, в теории я откровенно плаваю, и также мало практики. То, что в задачах встречается, то ковыряю, а более обширно поизучать не успел ещё, хотя надо бы взяться запрос такой (click to show) -- CReportsTableModel_History_Button_Load
-- полный запрос - история событий
select
-- id первого события
t1_event_id as event_id
-- code первого события
,t1_event_code as event_code
-- гуид задания
,t1_Task_guid as Task_guid
-- кнопка
,t1_Button_num as Button_num
-- время последнего сообщения
,t6_date_from_archive_xxx_LAST as date_from_archive_xxx_LAST
-- получено
,t1_date_from_archive_xxx as date_from_archive_xxx
-- код последнего события s_protocol_TCPRSP::ee_EVENT_code
,t6_event_code_LAST as event_code_LAST
-- время выполнения
,TIMESTAMPDIFF(SECOND, t1_date_from_archive_xxx, t6_date_from_archive_xxx_LAST) as dt_sec
from
(
select
`BPA_uid`
,`event_id` t1_event_id
,`event_code` t1_event_code
,`Button_num` t1_Button_num
,`date_from_archive_xxx` t1_date_from_archive_xxx
,`Task_guid` t1_Task_guid
from `events_table` where true
and
((
-- ("+show_resets/+")
true
and `event_code` in
(
4 -- EV_TASK_GOT
,7 -- EV_TASK_DONE
,8 -- EV_TASK_REPEATED
,15 -- EV_TASK_DONE_REPEATED
)
)
or
(
-- not("+show_resets/+")
not true
and `event_code` in
(
4 -- EV_TASK_GOT
)
))
-- "+and_GRP_equal_N/+"
and `grp`=2
and date_from_archive_xxx is not null
-- "+and_date_from_archive_xxx_moreequal_t1/+"
and date_from_archive_xxx >= '0000-00-00'
-- "+and_date_from_archive_xxx_lessequal_t2/+"
and date_from_archive_xxx <= '9999-00-00'
order by `event_id` desc
)t1
left join
( -- id последнего события
select
max(`event_id`) t5_event_id_LAST
,`Task_guid` t5_Task_guid
from `events_table`
where true
and `event_code` in
(
7 -- EV_TASK_DONE
)
group by t5_Task_guid
)t5
on
(
true
and t5.t5_Task_guid=t1.t1_Task_guid
and t1.t1_event_code=4 -- EV_TASK_GOT
)
left join
(
-- время последнего события (не повторного сброса)
-- код последнего события (не повторного сброса)
select
`event_id` t6_event_id_LAST
,`event_code` t6_event_code_LAST -- s_protocol_TCPRSP::ee_EVENT_code
,`date_from_archive_xxx` t6_date_from_archive_xxx_LAST
from `events_table`
)t6
on
(
true
and t6.t6_event_id_LAST=t5.t5_event_id_LAST
)
order by `event_id` desc
;
комментарии типа -- ("+show_resets/+") - это мне для вставки в приложение напоминалки (про хранимую процедуру сейчас не надо, я знаю про них  ) таблицы и explain (click to show) CREATE TABLE `events_table` (
`event_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`event_code` int(10) unsigned NOT NULL COMMENT 'C_DBData_Events::s_data::ee_event_code',
`Task_guid` varchar(32) COLLATE utf8_unicode_ci NOT NULL DEFAULT '0',
`date_when_inserted` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`date_when_created_utc` datetime NOT NULL,
`ms_when_created` smallint(5) unsigned NOT NULL,
`date_Task_tobe_later_utc` datetime DEFAULT NULL,
`articul` varchar(16) COLLATE utf8_unicode_ci DEFAULT NULL,
`Pager_num` int(10) unsigned DEFAULT NULL,
`Button_num` int(10) unsigned DEFAULT NULL,
`sending_try_nzb` int(10) unsigned NOT NULL DEFAULT '0',
`executing_time_seconds` int(10) unsigned DEFAULT NULL,
`deliver_type` tinyint(3) unsigned DEFAULT NULL COMMENT 's_protocol_TCPRSP::ee_deliver_type',
`BPA_uid` bigint(20) unsigned DEFAULT NULL,
`grp` int(10) DEFAULT NULL,
`date_from_archive_xxx` datetime DEFAULT NULL,
`src_class` int(10) unsigned DEFAULT NULL,
`src_addr` int(10) unsigned DEFAULT NULL,
PRIMARY KEY (`event_id`),
UNIQUE KEY `event_id_UNIQUE` (`event_id`),
UNIQUE KEY `_event_bufftime_ADDR_CLAS_BPA_GRP_UNIQUE` (`date_from_archive_xxx`,`src_addr`,`src_class`,`BPA_uid`,`grp`),
KEY `event_code_notUNIQUE` (`event_code`),
KEY `Task_guid_notUNIQUE` (`Task_guid`),
KEY `date_when_created_utc_notUNIQUE` (`date_when_created_utc`),
KEY `Button_num_notUNIQUE` (`Button_num`),
KEY `deliver_type_notUNIQUE` (`deliver_type`),
KEY `BPA_uid_notUNIQUE` (`BPA_uid`),
KEY `grp_notUNIQUE` (`grp`),
KEY `date_from_archive_xxx_notUNIQUE` (`date_from_archive_xxx`),
KEY `src_class_notUNIQUE` (`src_class`),
KEY `src_addr_notUNIQUE` (`src_addr`)
) ENGINE=InnoDB AUTO_INCREMENT=1280 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci
CREATE TABLE `buttons` (
`uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`button_number` int(10) unsigned NOT NULL,
`articul` varchar(16) COLLATE utf8_unicode_ci DEFAULT NULL,
`charge_level` int(10) unsigned DEFAULT NULL,
`comment` varchar(1024) COLLATE utf8_unicode_ci DEFAULT NULL,
`date_when_refreshed_utc` datetime DEFAULT NULL,
`radiogroup` int(10) unsigned DEFAULT NULL,
`PagersHumansLinks` blob,
`date_when_Button_updated_utc` datetime DEFAULT NULL,
PRIMARY KEY (`uid`),
UNIQUE KEY `uid_UNIQUE` (`uid`),
UNIQUE KEY `button_number_UNIQUE` (`button_number`),
KEY `date_when_Button_updated_utc_notUNIQUE` (`date_when_Button_updated_utc`)
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci 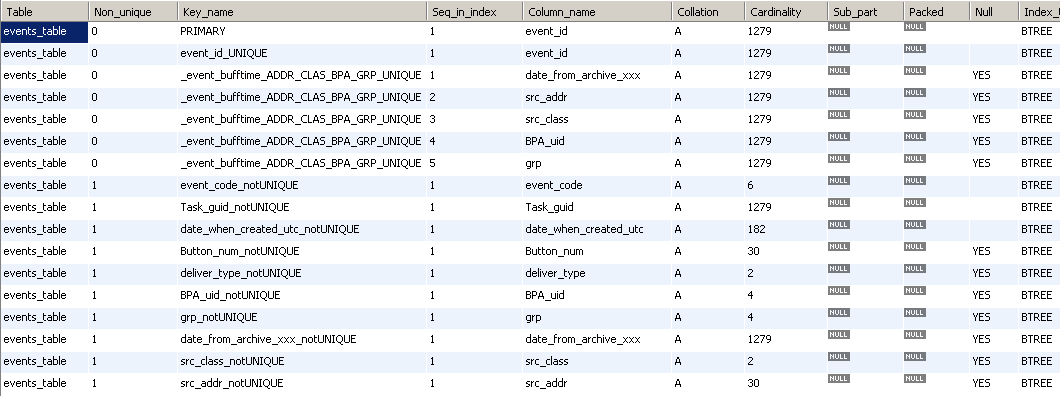   вопрос возникнет, зачем у меня where true ... - это для удобства, чтобы условия and добавлять и убирать удобнее было. В общем, можно не обращать внимания )
|
 1.png 1.png (26.23 Кб - загружено 1753 раз.)
2.png (7.08 Кб - загружено 1699 раз.)
3.png (9.24 Кб - загружено 1763 раз.)
|
|
« Последнее редактирование: 12-10-2015 15:00 от Алексей1153 »
|
Записан
|
|
|
|
|
Sla
|
|
« Ответ #18 : 12-10-2015 18:34 » |
|
Я бы сказал... ПЕРЕПИСЫВАЙ -- CReportsTableModel_History_Button_Load
-- полный запрос - история событий
select
-- id первого события
t1_event_id as event_id
-- code первого события
,t1_event_code as event_code
-- гуид задания
,t1_Task_guid as Task_guid
-- кнопка
,t1_Button_num as Button_num
-- время последнего сообщения
,t6_date_from_archive_xxx_LAST as date_from_archive_xxx_LAST
-- получено
,t1_date_from_archive_xxx as date_from_archive_xxx
-- код последнего события s_protocol_TCPRSP::ee_EVENT_code
,t6_event_code_LAST as event_code_LAST
-- время выполнения
,TIMESTAMPDIFF(SECOND, t1_date_from_archive_xxx, t6_date_from_archive_xxx_LAST) as dt_sec
from
(
select
`BPA_uid`
,`event_id` t1_event_id
,`event_code` t1_event_code
,`Button_num` t1_Button_num
,`date_from_archive_xxx` t1_date_from_archive_xxx
,`Task_guid` t1_Task_guid
from `events_table` where true
and
((
-- ("+show_resets/+")
true
and `event_code` in
(
4 -- EV_TASK_GOT
,7 -- EV_TASK_DONE
,8 -- EV_TASK_REPEATED
,15 -- EV_TASK_DONE_REPEATED
)
)
or
(
-- not("+show_resets/+")
not true
and `event_code` in
(
4 -- EV_TASK_GOT
)
))
-- "+and_GRP_equal_N/+"
and `grp`=2
and date_from_archive_xxx is not null
-- "+and_date_from_archive_xxx_moreequal_t1/+"
and date_from_archive_xxx >= '0000-00-00'
-- "+and_date_from_archive_xxx_lessequal_t2/+"
and date_from_archive_xxx <= '9999-00-00'
order by `event_id` desc
)t1
left join
( -- id последнего события
select
max(`event_id`) t5_event_id_LAST
,`Task_guid` t5_Task_guid
from `events_table`
where true
and `event_code` in
(
7 -- EV_TASK_DONE
)
group by t5_Task_guid
)t5
on
(
true
and t5.t5_Task_guid=t1.t1_Task_guid
and t1.t1_event_code=4 -- EV_TASK_GOT
)
left join
(
-- время последнего события (не повторного сброса)
-- код последнего события (не повторного сброса)
select
`event_id` t6_event_id_LAST
,`event_code` t6_event_code_LAST -- s_protocol_TCPRSP::ee_EVENT_code
,`date_from_archive_xxx` t6_date_from_archive_xxx_LAST
from `events_table`
)t6
on
(
true
and t6.t6_event_id_LAST=t5.t5_event_id_LAST
)
order by `event_id` desc Вот это ... явно and t1.t1_event_code=4 -- EV_TASK_GOT НИКУДА не годится!!! У тебя t5 и t6 никак не связываются с t1 ЭТО and t1.t1_event_code=4 -- EV_TASK_GOT Никак не не связывает |
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
HandKot
Молодой специалист
Offline
|
|
« Ответ #19 : 13-10-2015 10:26 » |
|
Я бы сказал... ПЕРЕПИСЫВАЙ
...
Вот это ... явно
and t1.t1_event_code=4 -- EV_TASK_GOT НИКУДА не годится!!!
У тебя t5 и t6 никак не связываются с t1
ЭТО
and t1.t1_event_code=4 -- EV_TASK_GOT
Никак не не связывает
может хотелось, чтобы данные о максимальном событии вязалось только к событию EV_TASK_GOT. остальные только для информации ЗЫЖ Алексей++ выложите структуру таблиц с тестовыми данными и то что хотите получить от запроса. А то по самому запросу как-то не особо врубаюсь, что Вы хотите |
|
|
|
|
Записан
|
I Have Nine Lives You Have One Only
THINK!
|
|
|
|
RXL
|
|
« Ответ #20 : 13-10-2015 15:57 » |
|
Дофига индексов и сомневаюсь, что все они используются. MySQL использует только один индекс при выборке из таблицы. По этому он должен стараться быть оптимальным. Далее... where true and `event_code` in ( 7 -- EV_TASK_DONE ) group by t5_Task_guid )t5 on ( true and t5.t5_Task_guid=t1.t1_Task_guid and t1.t1_event_code=4 -- EV_TASK_GOT )
И как это должно исполняться? Не, Леш, так писать нельзя. Таблица одна - делай один запрос с набором параметров, а не кучу подзапросов. Это будет легче понять и оптимизировать. Добавлено через 15 минут и 29 секунд: AND date_from_archive_xxx IS NOT NULL
AND date_from_archive_xxx >= '0000-00-00'
AND date_from_archive_xxx <= '9999-00-00' Обои три строки бесполезны. Сравнение с NULL всегда даст лож. Сравнение столбца DATE с '0000-00-00' бессмысленно - так отображаются DATE NULL. Советую в мануал заглянуть: https://dev.mysql.com/doc/refman/5.5/en/datetime.htmlВ общем, если я правильно понял, ты хочешь просто валидную дату. Если ты не вставляешь невалидных дат (DATE может быть невалидной), IS NOT NULL достаточно. Опять же, если я тебя правильно понял, то запрос выглядит так: SELECT
event_id
, event_code
, Task_guid
, Button_num
, date_from_archive_xxx_LAST
, date_from_archive_xxx
, event_code_LAST
, TIMESTAMPDIFF(SECOND, date_from_archive_xxx, date_from_archive_xxx_LAST) as dt_sec
FROM events_table t1
WHERE event_code IN (4, 7, 8, 15)
AND grp = 2
AND date_from_archive_xxx IS NOT NULL
AND t1.event_id = (
SELECT max(t2.event_id)
FROM events_table t2
WHERE t1.Task_guid = t2.Task_guid
AND t2.event_code = 4 -- или 7 - определись уже!
)
ORDER BY event_id DESC Индексы для этого запроса: UNIQUE KEY (Task_guid, event_code, event_id) KEY (grp, event_code, event_id) Но не уверен - смущаю твои LEFT JOIN. Не знаю, нужны ли они или ты их просто так поставил. |
|
|
|
« Последнее редактирование: 13-10-2015 16:19 от RXL »
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #21 : 13-10-2015 19:00 » |
|
HandKot, RXL, Sla,
никак мне не дают добраться до форума, завтра постараюсь внимательно прочитать и ответить )) И что я пытаюсь сделать (и даже сделал как-то, но оптимизацию, думаю, точно можно делать, я даже пока не беру во внимание перенос в хранимые процедуры, пока не до этого, тут аврал )
Но, Слава, ты точно не прав - они ещё как связываются.
Ром, индексы я добавлял там, где реально нужен поиск (а вовсе не в обратном порядке наобум), так что они используются, но количество их меня самого пугает - можно ли так делать. Пока работает , там запрос даже больше стал чуток
Про сравнение трёх строк со временем - это шаблон, чтобы потом в процедуру переносить, на месте строк там подставится реальное время
|
|
|
|
« Последнее редактирование: 13-10-2015 19:03 от Алексей++ »
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #22 : 13-10-2015 23:27 » |
|
На счет DATE и DATETIME: минимальная дата 1000-01-01. Сравнение диапазонов - BETWEEN. Дополнять сравнение проверкой IS NOT NULL не нужно.
|
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #23 : 18-10-2015 10:53 » |
|
в общем, действительно усложняться стал запрос, я решил радикально упростить - вытаскиваю события по некоторым условиям без всяких дополнительный расчётов при помощи СУБД, а всё пересчитываю в программе  Даже погибче оказалось, хотя упражнения с запросами были забавные Кстати, в книге Дэна Тоу упоминается, что если использовать Oracle, то можно чуть ли не всегда содержать базу данных целиком (то есть, не сохраняя "вручную" часть длинных накапливающихся таблиц). Меня данный момент очень интересует. Или что там имеется в виду ? |
|
|
|
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #24 : 18-10-2015 22:53 » |
|
Кстати, в книге Дэна Тоу упоминается, что если использовать Oracle, то можно чуть ли не всегда содержать базу данных целиком (то есть, не сохраняя "вручную" часть длинных накапливающихся таблиц). Меня данный момент очень интересует. Или что там имеется в виду ?
Очень непонятная формулировка. Особенно: «содержать базу данных целиком» и «не сохраняя "вручную" часть длинных накапливающихся таблиц». Или очень кривой перевод, или вырвано из контекста. В любом случае не стоит думать о панацее — ее просто не существует. |
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #25 : 19-10-2015 05:59 » |
|
RXL, нет там никаких переводов, это моя фраза )) Ну, я так и подумал, что халявы не будет
|
|
|
|
|
Записан
|
|
|
|
|
Sla
|
|
« Ответ #26 : 19-10-2015 09:10 » |
|
может речь идет о tempory tablespace, которая располагается в памяти.
Т.е. идея в том, что можно настроить tablespace, так что она будет располагаться в памяти, при загрузке сервера, все пространство (или часть) копируется в память, и работа происходит уже с ОЗУ.
|
|
|
|
|
Записан
|
Мы все учились понемногу... Чему-нибудь и как-нибудь.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #27 : 20-10-2015 05:28 » |
|
вот скрин оттуда Добавлено через 1 минуту и 54 секунды:Если там реально так всё сказочно, можно подумать о переходе на Oracle на одном из проектов, там лог заполняется постоянно, и необходимо скидывать "историю" , а потом её и просматривать есть необходимость |
|
|
« Последнее редактирование: 20-10-2015 05:30 от Алексей++ »
|
Записан
|
|
|
|
|
Dale
|
|
« Ответ #28 : 20-10-2015 06:52 » |
|
Монополия Oracle на "разбиения" давно осталась в прошлом. Например, в MS SQL имеется (как минимум начиная с версии 2005) аналогичная фича, только они называют ее "секционированием таблиц". Вполне вероятно, что и на других платформах есть нечто подобное. Так что если это единственная причина переползания на Oracle, не торопитесь с решением. Тем более что политика лицензирования у них, мягко говоря, не самая дружественная к потребителю.
|
|
|
|
|
Записан
|
Всего лишь неделя кодирования с последующей неделей отладки могут сэкономить целый час, потраченный на планирование программы. - Дж. Коплин.
Ходить по воде и разрабатывать программное обеспечение по спецификациям очень просто, когда и то, и другое заморожено. - Edward V. Berard
Любые проблемы в информатике решаются добавлением еще одного уровня косвенности – кроме, разумеется, проблемы переизбытка уровней косвенности. — Дэвид Уилер.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #29 : 20-10-2015 08:17 » |
|
Dale, понятно. Ну да, книге то уже 10 лет, я и не подумал
|
|
|
|
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #30 : 20-10-2015 09:52 » |
|
Partition есть уже даже в MySQL и причем давно. Только это тоже не панацея и бить таблицу в несколько десятков метров, мягко говоря, преждевременно.
|
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #31 : 20-10-2015 19:17 » |
|
абстрактный вопрос! имеется таблица `группа`,`А`,`Б` в пределах группы значения А должны быть уникальны, также значения Б должны быть уникальны группа A Б
1 2 2
1 2 3 - нельзя , повторилось значение А
1 4 8 - можно
1 7 3 - нельзя , повторилось значение Б
2 2 2 - можно, поскольку группа сменилась
2 4 8 - можно
2 4 7 - нельзя
Возможно ли добавить такой контроль средствами базы, при помощи ключей ? Составной ключ тут явно не катит, что-то похитрее нужно. Добавлено через 1 минуту и 15 секунд:есть, однако, предположение, что два уникальных составных индекса могут помочь (группа,А) (группа,Б) только выглядит как-то коряво |
|
|
|
« Последнее редактирование: 20-10-2015 19:19 от Алексей1153 »
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #32 : 20-10-2015 19:37 » |
|
Все верно, два UNIQUE KEY. Если это только ограничитель вставки, то порядок полей не важен. Если индекс используется для выборки, то важен.
Более сложные ограничения возможны с триггерами, но это сильно замедляет вставку. Если вставка редка, то можно и триггерами.
|
|
|
|
« Последнее редактирование: 20-10-2015 19:40 от RXL »
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #33 : 21-10-2015 04:45 » |
|
спасибо
это таблица - справочник, скорость вставки и выборки вроде не критичны совершенно. В отличие от такой проверки
|
|
|
|
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #34 : 21-10-2015 08:53 » |
|
Версия MySQL сервера какая?
|
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
Алексей++
глобальный и пушистый
Глобальный модератор
Offline
Сообщений: 13
|
|
« Ответ #35 : 22-10-2015 05:00 » |
|
версия 5.6
|
|
|
|
|
Записан
|
|
|
|
|
RXL
|
|
« Ответ #36 : 22-10-2015 10:59 » |
|
Норм. Исключения в процедурах и триггерах поддерживаются.
|
|
|
|
|
Записан
|
... мы преодолеваем эту трудность без синтеза распределенных прототипов. (с) Жуков М.С.
|
|
|
|
